


Simple solutions for common data pipeline challenges

Real solutions for real streaming challenges
Transform streams into embeddings for real-time AI search and recommendations
Process Kafka topics and message queues with simple YAML configuration
Handle IoT sensors, logs, and live data streams without complex code
Connect and transform API data streams automatically
Transform any data source to any target with simple YAML configurations. DataYoga Transform handles the rest.
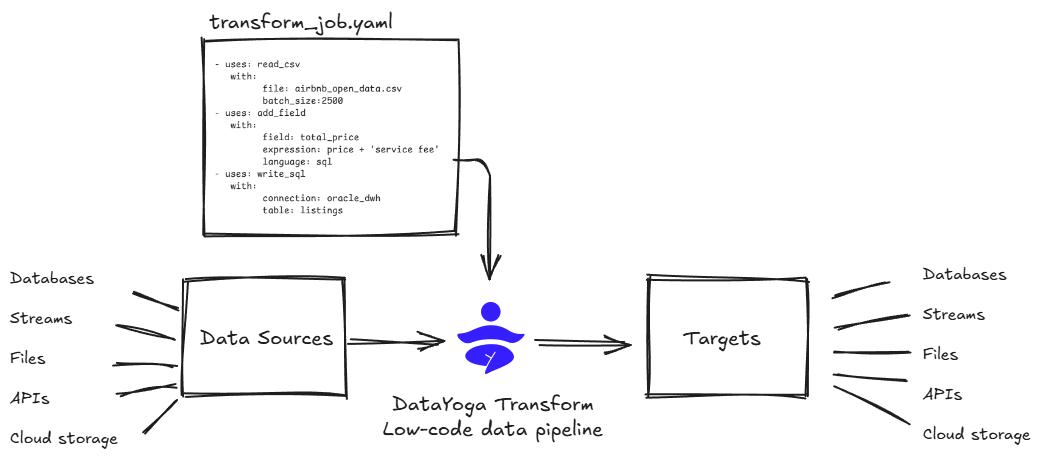
Run your first data pipeline with our built-in example
Run 'pip install datayoga' to install the framework
Run 'datayoga init hello_world' to create a new project with examples
Execute 'datayoga run sample.hello' to transform and display sample user data
Flexible integrations across diverse sources and targets
source:
type: kafka
topic: user-content
transform:
type: embedding
model: openai
target:
type: vectordb
store: pinecone # or milvus/weaviate/etc
index: real-time-content
source:
type: rest-api
endpoint: /events
target:
type: rabbitmq
source:
type: file
pattern: "*.log"
target:
type: elasticsearch
Common questions about DataYoga Transform
DataYoga Transform focuses on simplicity and flexibility. Instead of complex workflows or proprietary interfaces, you define pipelines in simple YAML files. This means faster development, easier maintenance, and no vendor lock-in.
Yes! DataYoga Transform is designed to complement your existing stack. Use it for specific pipelines while keeping your current tools, or gradually migrate processes as needed.
Absolutely! DataYoga Transform makes it easy to build AI-enabled data pipelines. You can transform data streams into embeddings, connect to vector databases, and power real-time AI applications - all using the same simple YAML configuration you use for traditional pipelines.
Not at all. While DataYoga is built in Python, you define pipelines using YAML configuration files. No Python coding required for standard pipelines.
DataYoga Transform handles everything from simple one-off pipelines to production streaming workloads. Built-in features like back-pressure handling and checkpointing ensure reliable processing at scale.
Yes! While the built-in blocks cover most needs, you can easily create custom blocks for specific requirements. The pluggable architecture makes extending functionality straightforward.
Start building flexible pipelines in minutes with DataYoga Transform